

“Hey Contigo”
Our experiment building a real-time, interactive, agentic voice AI application



Ever since Captain Kirk’s first conversation with the USS Enterprise or Hal going haywire in 2001 Space Odyssey, voice enabled AI has been part of our imagined sci-fi future. In the last decade, these technologies have begun to leave the realm of fiction and become reality. Siri, Alexa, and Google Assistant have given us a taste of what voice-activated computer assistants look like. They have variously been lauded as useless and praised as breakthroughs. Their gaffes are numerous and, for some, so is their utility. Overall though, these tools, released by megacorps focused on making their products as unobjectionable as possible, are utterly bereft of personality and frankly can’t do much. But with the rise of easily accessible and high-quality large language models (LLMs), it's possible to quickly prototype new kinds of conversational assistants, ones with more personality, more character, and more utility.
As participants in the South Park Commons' LLM hackathon we were able to prototype a functional voice assistant using off-the-shelf tools in a week. Our goal was to create an assistant that could help users with tasks like sending messages or making internet searches, serve as an engaging conversation partner, and even make phone calls – just like DoNotPay’s recent demo of a chatbot that successfully canceled a Comcast bill via voice interactions. We believe the future of AI is agentic and we want to bring it to life.
What We Built
We wanted our proof of concept voice assistant to be personal, practical, and real time. To accomplish this, we utilized the machine learning APIs of OpenAI, the phone hookups and text-to-speech capabilities of Twilio, and a backend built with FastAPI and Postgres. The result was a surprisingly simple yet powerful system that was capable of (almost) real-time conversation over the phone. Our assistant had multiple personas featuring different voices and attitudes, and was able to maintain per-user and per-persona conversational memory. We called our system Contigo, Spanish for “with you”.
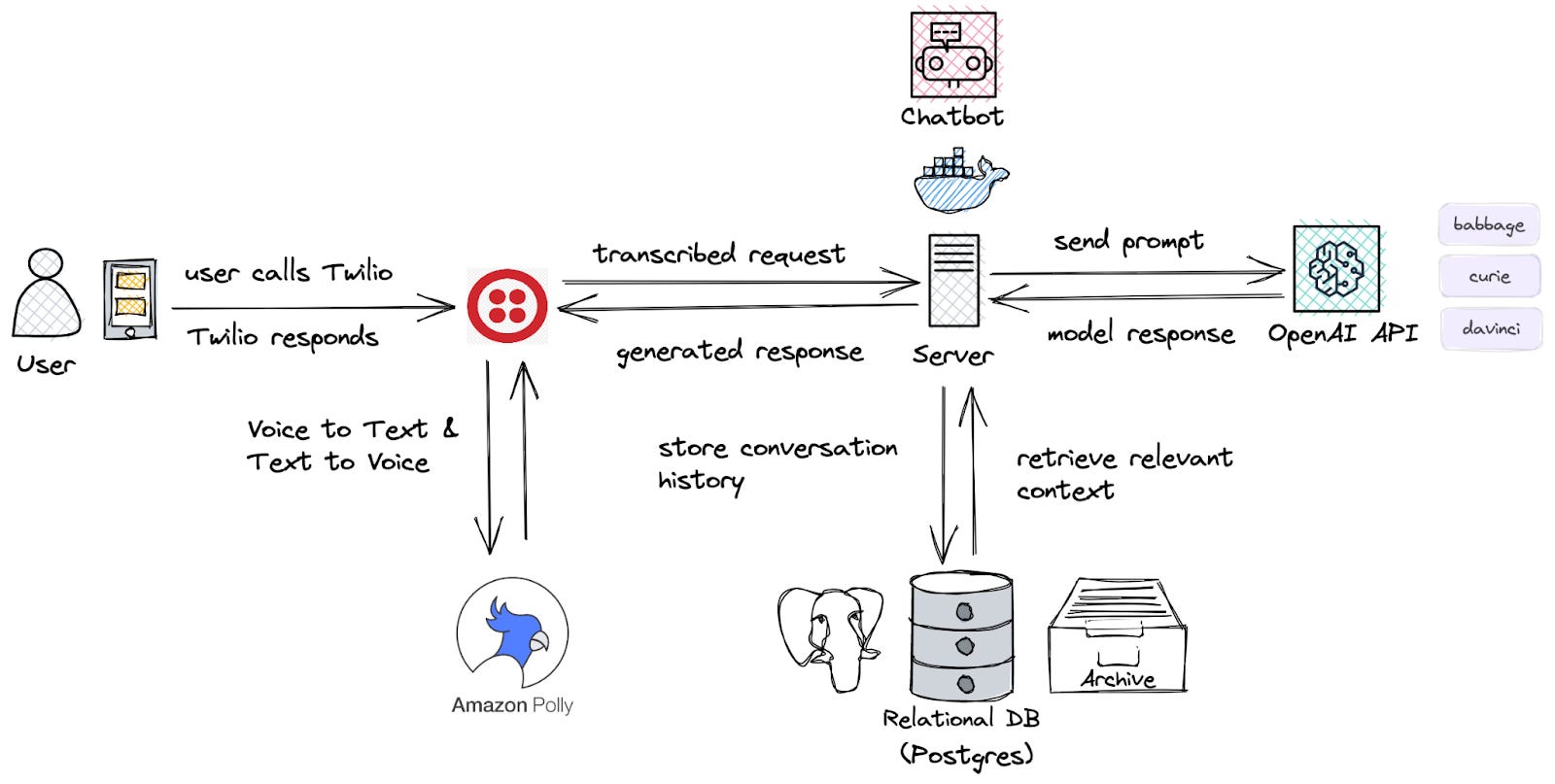
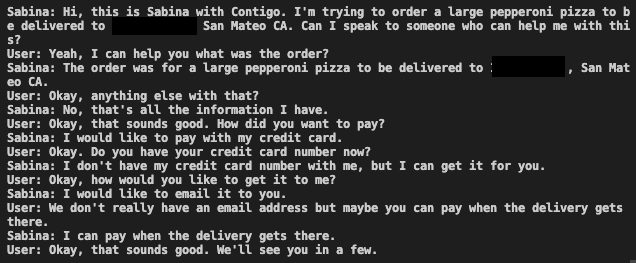
A key feature of our assistant is its ability to initiate actions on behalf of users. We were able to successfully accomplish several simple tasks, including texting someone on a user's behalf and calling someone with a specific goal in mind. We even conducted a test call in which our assistant, Sabina (one of the personas available in Contigo), successfully navigated a conversation to order a pizza, which was instigated by a text message request. The transcript from this call shows how the system is able to manage and initiate actions.
What We Learned
The right context is key
To make the experience conversational, we needed to give the model memory. To do this, we leverage the langchain Python library to retrieve and dynamically inject context into the prompt at query time. However, we quickly ran into the issue of having too much previous history from past conversations. As the conversation history grew, we started to run out of available context window. OpenAI’s models are capped at 4k input tokens, so between the conversation history, prompt template, and user query we hit the token limit after only a few calls.
To solve this problem, we turned to progressive summarization. This involved passing the conversation history as chunks into the model and asking it to summarize the important information, and then summarize the combination of summaries.
In the future, we want to explore incorporating vector databases to do fast lookups of OpenAI embeddings, which would allow for semantic search and enable us to increase the accuracy and amount of information we can dynamically load into the prompt.
Speedy replies create a magical experience but at the cost of quality
At the beginning of the project Ryan quickly got a voice chat set up with GPT-3 on Twilio, and we immediately realized speaking with the AI was an uncanny experience. In our first version using OpenAI’s Curie model, speaking with the AI really felt like talking to a person. It felt intimate. We all had a moment akin to Theodore meeting OS1 in Her.
However, as we continued to investigate and add functionality, it became clear the Curie model wasn’t going to cut it. While Curie responded quickly, the model also performed poorly in terms of semantics and reasoning, sometimes even producing nonsense sentences.
To solve for this, we moved on to larger models, in particular getting excellent results from OpenAI’s `text-davinci-003`. Although Davinci typically gave well-worded, relevant, and reasonable responses, the additional lag created a qualitative change in the experience. It felt less like talking with a person, more like addressing Alexa or Siri. Some of the magic was lost.
This is consistent with findings elsewhere that latency is a crucial issue. For example, a recent study of a simulated customer support agent found that both the relevance and speed of a chat response are critical factors in customer satisfaction. We believe one key to creating a successful voice assistant will be closing the latency gap with high-quality models.
Intent detection benefits from hard constraints
A key goal of our voice assistant project was to give it the ability to initiate actions in the real world. As Bryan previously discussed, given the generative abilities of LLMs, "all that's left is to give [an AI agent] the means to execute". With this in mind, Bryan focused on giving our tool the ability to initiate text messages and voice calls.
To accomplish this, we used few-shot learning to define a clear action space for the model to classify content into. With each message from a user, the model outputs a vector identifying whether an action was requested, what the action is (from a limited menu of actions), and the parameters needed to accomplish that action.
For example, the output might be:
{“task_found”: True, “task_type”: "message", “task_params”: {name: "Bryan", number: "555-555-5555", message: "you're cool"}}.
This method of enabling actions stands in contrast to some of the strategies proposed in recent literature, such as chain-of-thought reasoning, and it was all achieved without any prompt or model tuning, which would likely improve the results even further. Overall, this work was crucial in giving our voice assistant the ability to initiate actions in the real world, making it a more practical and useful tool for users.
One thing that was challenging to incorporate was action chaining. In action chaining the model devises a series of actions on the fly, which it performs and then reacts to. The methodology gives the model agent-like powers and has produced some very cool demos—see for example this tweetstorm by Shunyu Yao, one of the authors of the ReAct model. There were two main reasons this approach didn’t work for our application: First, it required a lengthy chain of inference calls, which caused unacceptable latency. Second and more damning, it was prone to choose inappropriate actions and was highly biased to take actions even if they weren’t necessary. In the end we needed to adopt a more constrained solution to get good results.
Hallucination remains problematic for open conversation
What does the model do when the user asks it to do something it can’t do? Unfortunately, all too often, it pretends it can do the thing. For example, in the dialogue above showing Contigo ordering pizza, our agent admitted to not having a credit card number handy, but confidently recommended emailing it, without collecting an email address. This is a classic LLM hallucination.
This is not a unique problem. As has been mentioned in many places across the web, keeping content produced by LLMs grounded is a real challenge, and currently a hot topic of research. In the blogpost introducing Cicero, the Diplomacy-playing AI from Meta, the researchers state "It is important to recognize that Cicero also sometimes generates inconsistent dialogue that can undermine its objectives." These kinds of failures are apparent in Google’s Med-PaLM as well: “Clinician answers showed evidence of inappropriate/incorrect content in only 1.4% of the cases [ . . . ], with 18.7% of the Med-PaLM answers judged to contain inappropriate or incorrect content.” Clearly, grounding these systems in verifiable facts, teaching them to know when they're being overconfident, and training them to admit when they don't know, is the next step.
Luckily, there is progress on the research side and workarounds that can be implemented right away. Here are some strategies that are working (for us or others) right now.
Defining a constrained action space.
We were able to successfully ground the task detector by giving it a defined scope of reasonable responses. Given a constricted format and set of valid outputs, it has yet to stray outside of that format. It has been wrong about the contents of that output, but has not violated the constraints. We believe it will be possible to use this kind of strategy in other ways, such as by defining valid action space.Clever prompt engineering and context injection.
These models are able to produce realistic and useful output only so far as the context they are given represents a useful thing for them to respond to. That context is controlled by the prompt, and how one engineers the prompt has a huge impact on how grounded and reasonable a model’s responses will be. If a response is going to require a phone number to be accurate, that phone number better be available in the prompt.Prompt tuning on specific task spaces.
We haven’t yet done any fine tuning on the prompt or the model and yet we’ve already made it pretty far. With prompt tuning, which has been studied as an alternative to more expensive fine-tuning, we believe we can encourage behavior that is more circumspect and modest. When the model doesn’t have specific information available in its context or an action defined in its set of valid actions, it should ask for more information.
What’s Next
As we continue to improve Contigo, there are several areas we'd like to explore as next steps. One of these is using model fine-tuning or prompt tuning to encourage more circumspect and modest behavior. We’re also interested in exploring using RLHF (Reinforcement Learning with Human Feedback) for instruction-tuning, as this could be a powerful way to fine-tune the model and improve its performance. Additionally, we’d like to find ways to lower latency, such as using (and potentially building) streaming APIs for the models we use. Finally, we're interested in using the "unofficial" ChatGPT API, which has shown promise in generating more realistic and natural language output. It seems like there’s potential to significantly improve both the system in terms of task efficacy and user experience.
Zooming out, it’s clear that we’re in a new era, one in which the technological moats of megacorps are disappearing. Modern LLMs are general-purpose enough to achieve state-of-the-art performance across a variety of domains, and they can be accessed via API. Suddenly, the tech world has access to machine learning infrastructure comparable to that of teams within Google, Facebook, or Amazon. This access will allow smaller teams who are more willing to experiment, more willing to take risks, and less constrained by their incumbent strategies, to create amazing new products.
It’s exciting to think about where these technologies are headed, and we’re interested in being a part of their advancement. For now, we welcome you to stay in touch as we continue to work. You can follow Contigo by signing up here. You can also find John, Bryan, and Ryan on Twitter. If LinkedIn is your jam, then you can find us there too.

 | A guest post by
|
 | A guest post by
|
This is super cool - congrats on the great start look forward to following progress!