
Spotting the Difference
Thinking about the implications of AI reasoning for regulation, compliance, and law

As the world goes nutty for ‘agents’, I’m still stuck thinking about the implications of models dealing effectively with text and logical inference. To me, it seems that the root of many of the most interesting and performant applications of AI is using models to “spot the difference” between two collections of tokens.
This is the common thread between AI powered tools used to edit code, mark up a contract, determine whether a patient might have a disease, or understand whether an image of a house shows any HOA violations. All of these use cases share the paradigm of comparing one body of evidence (media1) against another (media2), and applying reason between them to draw conclusions. In NLP research, this paradigm is called Natural Language Inference (NLI) and it’s been around since 2005. The breakthrough is that modern generative models are able to perform their role in these tasks with a high degree of contextual understanding, intent recognition, and implication awareness.
The conceptual simplicity of ‘spot the difference’ belies the complexity of its implementation, which involves billions of parameters and vast training datasets.1 The success of these efforts has turned this technology from a theoretical construct into a potent force actively reshaping professional domains. Its impact is particularly evident in sectors characterized by large volumes of codified textual knowledge and complex, rule-based decision-making, such as law, regulatory compliance, and finance.
In these fields, the ability of these models to perform nuanced semantic comparisons is elevating them (or will elevant them) from theoretically interesting tools into indispensable "co-pilots" and "intelligent interpreters."
LegalTech as a leading indicator
Historically, looking to the conservative world of law for cutting edge applications of technology has been a fool’s errand. Just a few years ago, the legal sector was certainly not a place where most technologists would look for cutting edge applications of the newest methods. But the last few years have seen a paradigm shift. The advances in natural language processing have been too powerful to ignore, and it seems that the entire profession is undergoing a significant transformation, primarily driven by LLM-powered tools that excel at reasoning through and comparing legal text. In fact, many of the primary workflows of headsdown legal work can be represented as versions of ‘media1 vs media2’ comparison.
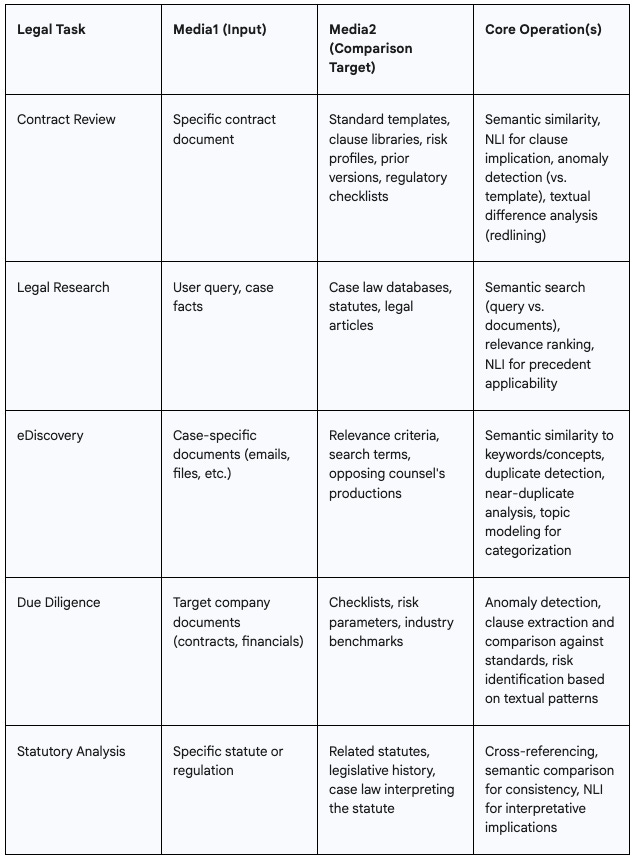
A substantial portion of legal work involves meticulous document review and analysis. With the right context, LLMs are now capable of comparing a given legal document—such as a contract, pleading, or piece of evidence (media1)—against various benchmarks (media2s). These benchmarks can include standard contractual templates, libraries of known clauses, predefined risk profiles, regulatory requirements, or even different versions of the same document to identify redlines and changes.
For another, legal research has traditionally been a labor-intensive process of sifting through vast databases of case law, statutes, and legal journals. LLMs are revolutionizing this by enabling more effective information retrieval and summarization. They can compare a user's natural language query or a description of case facts (media1) against immense digital libraries of legal texts (a massive collection of media2s) to find relevant precedents, supporting arguments, or contradictory rulings. Increasingly, they can then reason through the rulings to determine a correct (or at least legally defensible) line of argument to take.
Automating compliance
The logic of this framework, and the power of corresponding technologies, extends to other areas. Two of the most interesting (and potentially disruptive) are regulatory compliance and enforcement, which are heavily reliant on the interpretation and application of extensive textual rules.
Compliance automation tools increasingly leverage LLMs to compare an organization's internal policies, operational procedures, or transactional data (media1) against dense and often convoluted external regulations (media2). These systems can flag discrepancies, highlight areas of non-conformance, and identify potential risks, thereby helping organizations maintain adherence. For example, AI systems can cross-reference organizational processes with regulatory guidelines, automatically flagging instances of non-compliance for human review and remediation. This automates a highly complex, knowledge-intensive comparison task that previously demanded significant human expertise and time.
The domain of tax preparation, notorious for its complexity, is also changing from LLM-driven comparison. AI systems can take an individual's or a company's financial documents and transaction data (media1) and compare them against intricate and frequently updated tax codes and regulations (media2) to prepare accurate and compliant tax filings. These systems can analyze uploaded financial forms and interpret the data in the context of relevant tax laws, identifying applicable deductions, credits, and obligations. This direct application of "media1 (financial data) vs. media2 (tax law)" will reduce errors, maximize compliance, and streamline a burdensome process.
On the regulatory enforcement side, LLM-powered tools can transform claims evaluation. These systems can analyze detailed claim submissions including incident reports, medical records, and damage assessments (media1) and systematically compare them against the specific terms, conditions, and exclusions outlined in insurance policies (media2). The LLM can identify coverage boundaries, detect potential fraudulent patterns, and determine appropriate claim settlements based on policy language. Such a system can flag ambiguous situations where human judgment is needed while handling straightforward cases with greater consistency and efficiency. For policyholders, this means faster claim resolutions and more consistent outcomes; for insurers, it means reduced operational costs and more accurate risk management.
The potential for this technology across these diverse applications underscores that the "media vs. media" framework is particularly potent in domains characterized by large volumes of codified textual knowledge and clearly defined (though often complex) rules. The ability of LLMs to perform nuanced semantic comparison is what elevates them from basic search tools to "co-pilots" and "intelligent interpreters." This advanced capability directly causes the significant utility and the perception of "intelligence" in these professional applications. Consequently, as LLMs become increasingly adept at these comparative tasks, the definition of "routine work" in these professions is set to shift, pushing human professionals towards higher-level strategic thinking, complex judgment in novel situations, ethical decision-making, and interpersonal client interaction, as originally posited. The technology has the potential to fundamentally transform how we interface with ‘the bureaucracy’, acting as a smooth interface over processes that have historically been burdensome and expensive.
Open questions
Thinking through this, I’m left with two outstanding questions.
First, these tools having the potential to create a smooth(er) interface over the complex regulatory and legal landscape is a function of us living in a society ruled by law rather than arbitrary fiat. If the true implications of the law or the regulation or the rule can't be derived from the media representing it (such as in a system where corruption is the norm), then it's not 'machine readable'. There's not currently a way of representing the role of bribery in our compliance software. What happens if ‘secret rules’ become the primary ruleset?
Second, there's a risk of this 'smoothing' being very temporary. Perhaps the regulation's complexity and the burden will grow to match improvements in the baseline. Instead of requiring this kind of report, it will require a new kind, and instead of quarterly filing, weekly filing is now needed. One can imagine the burden growing as the sense of what is 'normal' changes. Will regulators incrementally increase the burden of evidence for compliance as gathering and evaluating the evidence gets faster?